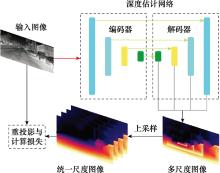
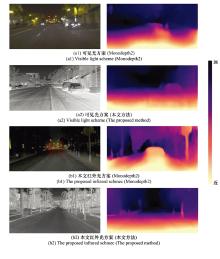
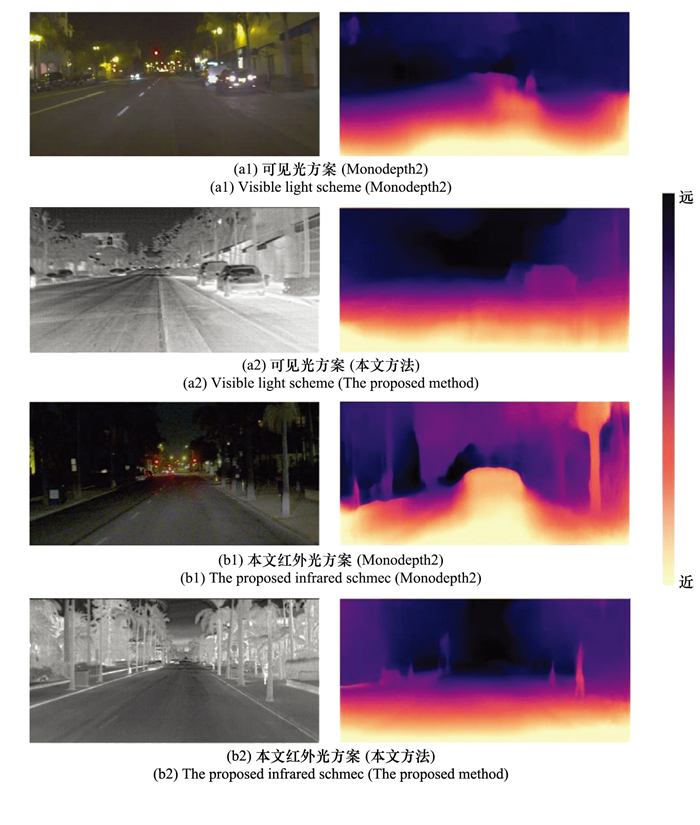
| 1 |
RANFT B , STILLER C . The role of machine vision for intelligent vehicles[J]. IEEE Trans.on Intelligent Vehicles, 2016, 1 (1): 8- 19.
doi: 10.1109/TIV.2016.2551553
|
| 2 |
HORGAN J, HUGHES C, MCDONALD J, et al. Vision-based driver assistance systems: survey, taxonomy and advances[C]//Proc. of the IEEE 18th International Conference on Intelligent Transportation Systems, 2015: 2032-2039.
|
| 3 |
ULLMAN S . The interpretation of structure from motion[J]. Proceedings of the Royal Society of London, 1979, 203 (1153): 405- 426.
|
| 4 |
ZHAO C Q, SUN Q Y, ZHANG C Z, et al. Monocular depth estimation based on deep learning: an overview[EB/OL]. [2020-03-14]. https://arxiv.org/pdf/2003.06620.
|
| 5 |
HUANG J , WANG C , LIU Y , et al. The progress of monocular depth estimation technology[J]. Journal of Image and Gra-phics, 2019, 24 (12): 2081- 2097.
|
| 6 |
EIGEN D, PUHRSCH C, FERGUS R. Depth map prediction from a single image using a multi-scale deep network[EB/OL]. [2014-06-09]. https://arxiv.org/abs/1406.2283.
|
| 7 |
KENDALL A, MARTIROSYAN H, DASGUPTA S, et al. End-to-end learning of geometry and context for deep stereo regression[C]//Proc. of the IEEE International Conference on Computer Vision, 2017: 66-75.
|
| 8 |
XU D, WANG W, TANG H, et al. Structured attention guided convolutional neural fields for monocular depth estimation[C]//Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2018: 3917-3925.
|
| 9 |
GARG R, VIJAY K B G, GUSTAVO C, et al. Unsupervised CNN for single view depth estimation: geometry to the rescue[C]//Proc. of the European Conference on Computer Vision, 2016: 740-756.
|
| 10 |
ZHOU T, BROWN M, SNAVELY N, et al. Lowe, unsupervised learning of depth and ego-motion from video[C]//Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2017: 1851-1858.
|
| 11 |
GEIGER A, LENZ P, URTASUN R. Are we ready for autonomous driving? the kitti vision benchmark suite[C]//Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2012: 3354-3361.
|
| 12 |
SAXENA A , SUN M , NG A Y . Make3D: learning 3D scene structure from a single still image[J]. IEEE Trans. on Pattern Analysis and Machine Intelligence, 2008, 31 (5): 824- 840.
|
| 13 |
RONNEBERGER O, FISCHER P, BROX T. U-Net: convolutional networks for biomedical image segmentation[C]//Proc. of the Medical Image Computing and Computer-Assisted Intervention, 2015: 234-241.
|
| 14 |
WANG Z , BOVIK A C , SHEIKH H R , et al. Image quality assessment: from error visibility to structural similarity[J]. IEEE Trans.on Image Processing, 2004, 13 (4): 600- 612.
doi: 10.1109/TIP.2003.819861
|
| 15 |
GODARD C, AODHA O M, BROSTOW G J. Unsupervised monocular depth estimation with left-right consistency[C]//Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2017: 270-279.
|
| 16 |
VIJAYANARASIMHAN S, RICCO S, SCHMID C, et al. SfM-net: learning of structure and motion from video[EB/OL]. [2017-02-25]. https://arxiv.org/abs/1704.07804.
|
| 17 |
CASSER V, PIRK S, MAHJOURIAN R, et al. Depth prediction without the sensors: leveraging structure for unsupervised learning from monocular videos[EB/OL]. [2019-06-12] https://arxiv.org/abs/1906.05717.
|
| 18 |
ODARD C, AODHA O M, FIRMAN M, et al. Digging into self-supervised monocular depth estimation[C]//Proc. of the IEEE International Conference on Computer Vision, 2019: 3828-3838.
|
| 19 |
KAIMING H , GEORGIA G , PIOTR D , et al. Mask R-CNN[J]. IEEE Trans. on Pattern Analysis and Machine Intelligence, 2018, 42 (2): 386- 397.
|
 ), Meng DING1(
), Meng DING1(