基于强化学习的改进三维A*算法在线航迹规划
Improved three-dimensional A* algorithm of real-time path planning based on reinforcement learning
基于强化学习的改进三维A*算法在线航迹规划 |
| 任智, 张栋, 唐硕 |
|
Improved three-dimensional A* algorithm of real-time path planning based on reinforcement learning |
| Zhi REN, Dong ZHANG, Shuo TANG |
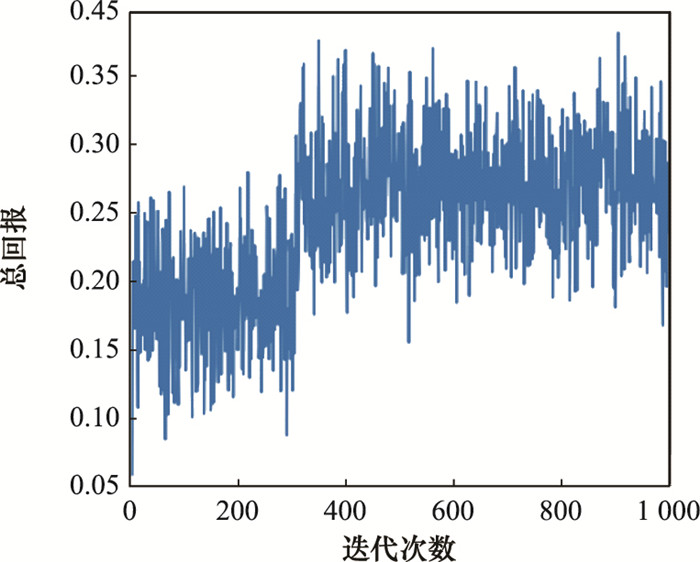
| 图11 迭代收敛的总回报图 |
| Fig.11 Diagram of total reward of iterative convergence |
|
|